https://colab.research.google.com/drive/
Google Colab Notebook
Run, share, and edit Python notebooks
colab.research.google.com

파이썬 range() 함수 설명
range() 함수는 숫자의 **연속적인 시퀀스(범위)**를 생성할 때 사용하는 파이썬 내장 함수입니다. 주로 반복문(for)과 함께 사용되어 특정 범위 내의 값을 순차적으로 처리합니다.
기본 문법
- start: 시작 값 (포함, 생략 시 기본값은 0)
- stop: 끝 값 (포함하지 않음, 필수)
- step: 증가 또는 감소 값 (생략 시 기본값은 1)
사용 예시
- 기본 사용출력:
-
코드 복사0 1 2 3 4
-
python코드 복사for i in range(5): # start=0, stop=5, step=1 print(i)
- 시작 값 지정출력:
-
코드 복사1 2 3 4
-
python코드 복사for i in range(1, 5): # start=1, stop=5, step=1 print(i)
- 증가값 지정출력:
-
코드 복사1 3 5 7 9
-
python코드 복사for i in range(1, 10, 2): # start=1, stop=10, step=2 print(i)
- 역순 처리출력:
-
코드 복사10 8 6 4 2
-
python코드 복사for i in range(10, 0, -2): # start=10, stop=0, step=-2 print(i)
range()의 특징
- 메모리 효율성:
- range()는 숫자를 미리 생성하지 않고, 필요할 때마다 생성하는 이터레이터 객체입니다.
- 이로 인해 메모리 사용량이 매우 적습니다.
-
scss코드 복사range(0, 5) [0, 1, 2, 3, 4]
-
python코드 복사print(range(5)) # range 객체 반환 print(list(range(5))) # 리스트로 변환
- 정수만 처리 가능:
- range()는 정수(int) 값만 사용할 수 있습니다. 실수를 사용할 경우 에러가 발생합니다.
python코드 복사range(1.0, 5.0) # TypeError 발생 - 조건 만족 시 종료:
- stop 값에 도달하면 반복이 종료됩니다. stop 값은 포함되지 않습니다.
활용 예시
- 리스트 값 처리
-
python코드 복사numbers = [10, 20, 30, 40, 50] for i in range(len(numbers)): # 인덱스 활용 print(f"Index {i}: {numbers[i]}")
- 짝수만 출력
-
python코드 복사for i in range(0, 11, 2): # 0부터 10까지 2씩 증가 print(i)
- 거꾸로 카운트다운
-
python코드 복사for i in range(10, 0, -1): print(i)
range()는 반복문과 함께 데이터를 순차적으로 처리하거나 특정 조건을 만족하는 숫자들을 다룰 때 매우 유용한 함수입니다!


코드 설명: a = list(map(int, input().split()))
이 코드는 파이썬에서 입력받은 문자열 데이터를 정수 리스트로 변환하는 과정을 수행합니다. 이를 단계별로 자세히 살펴보겠습니다.
코드의 주요 구성 요소
- input()
- 사용자로부터 한 줄의 문자열 입력을 받습니다.
- 예: 사용자가 1 2 3 4 5를 입력하면, input()은 "1 2 3 4 5"라는 문자열을 반환합니다.
- .split()
- 문자열을 공백 단위로 분리하여 리스트로 변환합니다.
- 예: "1 2 3 4 5".split() → ["1", "2", "3", "4", "5"]
- map(int, ...)
- 리스트의 각 요소를 정수(int)로 변환합니다.
- map 함수는 반복 가능한 객체의 요소에 지정된 함수를 하나씩 적용합니다.
- 예: map(int, ["1", "2", "3", "4", "5"]) → [1, 2, 3, 4, 5] (하지만 이 결과는 map 객체 형태)
- list()
- map 함수의 결과인 map 객체를 리스트로 변환합니다.
- 최종 결과: [1, 2, 3, 4, 5]
전체 코드 동작 흐름
- 사용자 입력: 1 2 3 4 5
- input() → "1 2 3 4 5"
- 공백으로 분리:
- input().split() → ["1", "2", "3", "4", "5"]
- 문자열을 정수로 변환:
- map(int, input().split()) → map 객체 (정수 변환 준비)
- 리스트 변환:
- list(map(int, input().split())) → [1, 2, 3, 4, 5]
예제 실행
입력:
코드:
출력:
활용 예시
- 리스트 합 계산:입력:출력:
-
plaintext코드 복사15
-
plaintext코드 복사1 2 3 4 5
-
python코드 복사a = list(map(int, input().split())) print(sum(a))
- 최댓값/최솟값 찾기:입력:출력:
-
plaintext코드 복사20 5
-
plaintext코드 복사10 5 20 15
-
python코드 복사a = list(map(int, input().split())) print(max(a), min(a))
- 정렬 후 출력:입력:출력:
-
plaintext코드 복사[1, 3, 4, 5, 8]
-
plaintext코드 복사5 3 8 1 4
-
python코드 복사a = list(map(int, input().split())) print(sorted(a))
요약
이 코드는 여러 개의 숫자를 공백으로 구분하여 입력받고, 이를 정수 리스트로 변환하는 일반적인 방식입니다. 반복적으로 숫자를 처리해야 하는 다양한 문제에서 자주 사용됩니다.


코드 설명
이 코드는 사용자로부터 입력을 받아 두 숫자의 합을 출력하는 프로그램입니다. 출력 형식은 각 테스트 케이스에 대해 Case #x: y의 형태로 결과를 표시합니다. 이를 단계별로 분석하겠습니다.
코드 흐름 분석
- N = int(input())
- 테스트 케이스의 수를 입력받습니다.
- 입력 예시: 3 (총 3개의 테스트 케이스)
- for number in range(N):
- 테스트 케이스의 수(N)만큼 반복문을 실행합니다.
- range(N)은 0부터 N-1까지의 정수를 생성합니다.
- 변수 number는 현재 반복 횟수를 나타냅니다.
- a = list(map(int, input().split()))
- 한 줄의 입력을 받아 공백으로 구분된 숫자들을 정수 리스트로 변환합니다.
- input().split() → 공백으로 구분된 문자열 리스트 반환 (예: ['1', '1'])
- map(int, ...) → 문자열 리스트를 정수 리스트로 변환 (예: [1, 1])
- 최종적으로 a는 두 정수가 들어 있는 리스트가 됩니다.
- print(f'Case #{number+1}: {a[0] + a[1]}')
- number+1은 현재 테스트 케이스 번호를 나타냅니다. (0부터 시작하므로 1을 더함)
- a[0]과 a[1]을 더한 값을 출력 형식에 맞게 표시합니다.
- 출력 형식: Case #테스트케이스번호: 합
실행 예제
입력:
코드 실행:
출력:
주요 포인트
- 반복 횟수:
- range(N)으로 테스트 케이스 횟수만큼 반복 수행.
- 입력 처리:
- input().split()으로 공백을 기준으로 입력을 분리.
- map(int, ...)으로 문자열을 정수로 변환.
- 리스트에 저장하여 인덱싱으로 각 숫자 접근 (a[0], a[1]).
- 출력 형식:
- f-string을 사용하여 문자열 포매팅.
- 테스트 케이스 번호와 결과를 형식에 맞게 출력.
수정 필요했던 코드 부분
원래 코드:
수정된 코드:
- 괄호 오류와 잘못된 변환(int(a[0] + int(a[1])) 수정.
- a[0]과 a[1]은 이미 정수형 리스트의 값이므로 추가 변환 불필요.
활용
이 코드는 여러 테스트 케이스의 데이터를 받아 계산 결과를 형식에 맞게 출력해야 하는 문제에서 자주 사용됩니다. 예를 들어:
- 두 숫자의 합 출력.
- 두 숫자의 곱 출력.
- 특정 연산을 여러 테스트 케이스에 반복 적용.
파이썬 딕셔너리(Dictionary)
파이썬의 딕셔너리는 키(key)와 값(value)의 쌍으로 데이터를 저장하는 자료구조입니다. 데이터를 빠르게 검색, 추가, 수정, 삭제할 수 있는 효율적인 데이터 타입입니다.
딕셔너리의 특징
- 키-값 쌍(Key-Value Pair)
- 데이터를 **키(key)**를 통해 접근하며, 각 키는 고유해야 합니다.
- 값(value)은 중복 가능하며, 다양한 데이터 타입을 가질 수 있습니다.
- 변경 가능
- 딕셔너리는 mutable(변경 가능)하며, 데이터 추가, 삭제, 수정이 가능합니다.
- 순서 보장 (파이썬 3.7부터)
- 삽입된 순서를 유지합니다.
- 해시 기반
- 키는 해시 가능(immutable, 예: 문자열, 숫자, 튜플 등)해야 합니다.
딕셔너리 생성
- 중괄호 사용
-
python코드 복사my_dict = {"name": "Alice", "age": 25, "city": "Seoul"}
- dict() 함수 사용
-
python코드 복사my_dict = dict(name="Alice", age=25, city="Seoul")
- 빈 딕셔너리 생성
-
python코드 복사my_dict = {}
딕셔너리 주요 기능
- 값 접근
-
python코드 복사my_dict = {"name": "Alice", "age": 25} print(my_dict["name"]) # 출력: Alice
- 값 변경
-
python코드 복사my_dict["age"] = 26 print(my_dict) # 출력: {'name': 'Alice', 'age': 26}
- 새로운 키-값 추가
-
python코드 복사my_dict["city"] = "Seoul" print(my_dict) # 출력: {'name': 'Alice', 'age': 26, 'city': 'Seoul'}
- 키 삭제
-
python코드 복사del my_dict["age"] print(my_dict) # 출력: {'name': 'Alice', 'city': 'Seoul'}
- get() 메서드로 안전하게 값 접근
- 키가 없는 경우 KeyError를 방지하며 기본값을 설정할 수 있습니다.
python코드 복사print(my_dict.get("age", "Not Found")) # 출력: Not Found - 키/값/아이템 확인
-
python코드 복사print(my_dict.keys()) # 키 목록: dict_keys(['name', 'city']) print(my_dict.values()) # 값 목록: dict_values(['Alice', 'Seoul']) print(my_dict.items()) # 아이템 목록: dict_items([('name', 'Alice'), ('city', 'Seoul')])
- 반복문 사용
-
python코드 복사for key, value in my_dict.items(): print(f"{key}: {value}")
딕셔너리 메서드
- update(): 다른 딕셔너리를 병합
-
python코드 복사my_dict.update({"country": "Korea", "city": "Busan"}) print(my_dict) # 출력: {'name': 'Alice', 'city': 'Busan', 'country': 'Korea'}
- pop(): 특정 키 제거 및 값 반환
-
python코드 복사age = my_dict.pop("age", "Not Found") print(age) # 키가 있으면 값 출력, 없으면 기본값 출력
- clear(): 모든 키-값 제거
-
python코드 복사my_dict.clear() print(my_dict) # 출력: {}
- copy(): 딕셔너리 복사
-
python코드 복사new_dict = my_dict.copy()
예제
- 학생 점수 관리 시스템
-
python코드 복사scores = {"Alice": 85, "Bob": 92, "Charlie": 78} # 학생 추가 scores["David"] = 88 # 점수 수정 scores["Alice"] = 90 # 특정 학생 점수 출력 print(scores["Bob"]) # 출력: 92 # 모든 학생의 평균 점수 계산 avg_score = sum(scores.values()) / len(scores) print(f"평균 점수: {avg_score}")
- 단어 빈도수 계산
-
python코드 복사text = "apple banana apple orange banana apple" word_count = {} for word in text.split(): word_count[word] = word_count.get(word, 0) + 1 print(word_count) # 출력: {'apple': 3, 'banana': 2, 'orange': 1}
딕셔너리 vs 리스트
특징딕셔너리리스트
| 데이터 구조 | 키-값 쌍 | 순차적 값 |
| 접근 속도 | 빠름 (키를 통한 접근) | 느림 (인덱스/검색 필요) |
| 사용 예시 | 데이터 매핑, 조회 | 순서 유지, 반복적 데이터 |
딕셔너리는 다양한 데이터를 체계적으로 관리하고 빠르게 접근할 수 있는 매우 강력한 자료구조입니다. 상황에 따라 유연하게 활용해 보세요!
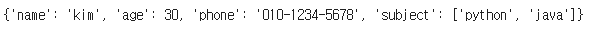
kim
30
010-1234-5678
['python', 'java']
female
{'name': 'kim', 'age': 30, 'phone': '010-1234-5678', 'subject': ['python', 'java']}
30
{'name': 'kim', 'phone': '010-1234-5678', 'subject': ['python', 'java']}
dict_keys(['name', 'phone', 'subject'])
name
phone
subject
name
phone
subject
kim
010-1234-5678
['python', 'java']
name : kim phone :
010-1234-5678
subject : ['python', 'java']
5 17
5
17
[('name', 'kim'), ('phone', '010-1234-5678'), ('subject', ['python', 'java'])]
[('subject', ['python', 'java']), ('phone', '010-1234-5678'), ('name', 'kim')]
파이썬 튜플(Tuple)
파이썬의 **튜플(tuple)**은 **변경 불가능(immutable)**한 순서가 있는 데이터 구조입니다. 리스트와 유사하지만, 값을 변경할 수 없다는 점에서 다릅니다.
튜플은 주로 변경되지 않아야 하는 데이터를 다룰 때 사용되며, 가벼운 자료구조로 리스트보다 메모리 효율이 좋습니다.
튜플의 특징
- 변경 불가능(Immutable):
- 생성된 이후 값을 추가, 삭제, 변경할 수 없습니다.
- 데이터의 안전성을 보장합니다.
- 순서 유지:
- 삽입된 순서를 유지하며, 인덱싱과 슬라이싱이 가능합니다.
- 다양한 데이터 타입 저장 가능:
- 문자열, 숫자, 리스트 등 다양한 데이터 타입을 함께 저장할 수 있습니다.
- 소괄호 사용:
- 튜플은 보통 **소괄호()**로 표현됩니다.
- 쉼표로 구분하여 작성하며, 소괄호는 생략 가능합니다.
- 가변 객체 포함 가능:
- 튜플 자체는 불변이지만, 가변 객체(예: 리스트)를 포함할 수 있습니다.
튜플 생성
- 소괄호 사용
-
python코드 복사my_tuple = (1, 2, 3)
- 쉼표로만 생성 (소괄호 생략 가능)
-
python코드 복사my_tuple = 1, 2, 3
- 한 개의 요소를 가진 튜플
- 반드시 쉼표를 포함해야 함
python코드 복사single_tuple = (5,) # 올바른 튜플 not_a_tuple = (5) # 단순 정수 - tuple() 함수 사용
-
python코드 복사my_tuple = tuple([1, 2, 3]) # 리스트를 튜플로 변환
튜플의 주요 기능
- 인덱싱(Indexing)
- 특정 위치의 요소에 접근
python코드 복사my_tuple = (10, 20, 30) print(my_tuple[0]) # 출력: 10 print(my_tuple[-1]) # 출력: 30 - 슬라이싱(Slicing)
- 부분적으로 잘라내기
python코드 복사print(my_tuple[1:]) # 출력: (20, 30) print(my_tuple[:2]) # 출력: (10, 20) - 길이 확인
-
python코드 복사print(len(my_tuple)) # 출력: 3
- 요소 존재 여부 확인
-
python코드 복사print(20 in my_tuple) # 출력: True print(40 not in my_tuple) # 출력: True
- 튜플 병합
-
python코드 복사tuple1 = (1, 2) tuple2 = (3, 4) result = tuple1 + tuple2 print(result) # 출력: (1, 2, 3, 4)
- 튜플 반복
-
python코드 복사print(tuple1 * 3) # 출력: (1, 2, 1, 2, 1, 2)
튜플 메서드
튜플은 불변이므로 사용 가능한 메서드가 제한적입니다.
- count(): 특정 요소의 개수 반환
-
python코드 복사my_tuple = (1, 2, 2, 3, 2) print(my_tuple.count(2)) # 출력: 3
- index(): 특정 요소의 첫 번째 인덱스 반환
-
python코드 복사print(my_tuple.index(3)) # 출력: 3
튜플과 리스트 비교
특징튜플(Tuple)리스트(List)
| 변경 가능 여부 | 불가능 (Immutable) | 가능 (Mutable) |
| 생성 시 사용 기호 | 소괄호 () | 대괄호 [] |
| 메모리 효율성 | 메모리 사용량 적음 | 메모리 사용량 많음 |
| 속도 | 접근 속도 빠름 | 다소 느림 |
| 사용 목적 | 변경 불필요한 데이터 저장 | 데이터의 추가, 삭제, 변경 |
활용 예시
- 변경되지 않는 데이터 그룹
- RGB 색상, 좌표값 등
python코드 복사rgb = (255, 255, 0) coordinates = (37.5665, 126.9780) - 다중 값 반환
-
python코드 복사def calculate(a, b): return a + b, a * b result = calculate(5, 3) print(result) # 출력: (8, 15)
- 튜플을 키로 사용하는 딕셔너리
- 튜플은 불변이므로 딕셔너리의 키로 사용 가능
python코드 복사my_dict = {("x", "y"): 10, ("a", "b"): 20} print(my_dict[("x", "y")]) # 출력: 10
튜플의 장점
- 데이터의 변경 방지가 필요한 경우 유용.
- 메모리 사용량이 적고 처리 속도가 빠름.
- 딕셔너리의 키 또는 집합(set)의 요소로 사용 가능.
튜플은 안정적이고 변경되지 않는 데이터를 다루는 데 적합합니다. 적절한 경우 리스트 대신 튜플을 사용하면 프로그램의 성능과 안정성을 향상시킬 수 있습니다.
{'a', 'b', 'c'}a
c
b
('a', 'a', 'a', 'b', 'b', 'c')
3
2
1
0
('a', 'a', 'a', 'b', 'b', 'c')
0
3
5
x : 20, y: 10


교집합, 합집합, 차집합: 이론과 파이썬 활용
집합 이론은 두 집합 간의 관계를 이해하는 데 중요한 개념입니다. 교집합, 합집합, 차집합은 각각 두 집합에서 공통되는 요소, 전체 요소, 특정 집합의 고유 요소를 찾는 연산입니다.
1. 교집합 (Intersection)
정의:
- 두 집합에서 공통으로 포함된 원소들의 집합입니다.
- 수학적 기호: A∩BA \cap B
특징:
- 교집합에 포함되는 원소는 두 집합 모두에 속해야 합니다.
예제:
- A={1,2,3},B={2,3,4}A = \{1, 2, 3\}, B = \{2, 3, 4\}
- A∩B={2,3}A \cap B = \{2, 3\}
파이썬 구현:
또는:
2. 합집합 (Union)
정의:
- 두 집합에서 하나라도 포함된 원소들의 집합입니다.
- 수학적 기호: A∪BA \cup B
특징:
- 중복되는 원소는 한 번만 포함됩니다.
예제:
- A={1,2,3},B={2,3,4}A = \{1, 2, 3\}, B = \{2, 3, 4\}
- A∪B={1,2,3,4}A \cup B = \{1, 2, 3, 4\}
파이썬 구현:
또는:
3. 차집합 (Difference)
정의:
- 한 집합에는 포함되고, 다른 집합에는 포함되지 않은 원소들의 집합입니다.
- 수학적 기호: A−BA - B
특징:
- A−BA - B는 집합 AA에서 BB의 원소를 제거한 결과입니다.
예제:
- A={1,2,3},B={2,3,4}A = \{1, 2, 3\}, B = \{2, 3, 4\}
- A−B={1}A - B = \{1\}
- B−A={4}B - A = \{4\}
파이썬 구현:
또는:
4. 대칭 차집합 (Symmetric Difference)
정의:
- 두 집합 중 하나에만 포함된 원소들의 집합입니다.
- 수학적 기호: A△BA \triangle B
특징:
- A△B=(A−B)∪(B−A)A \triangle B = (A - B) \cup (B - A)
예제:
- A={1,2,3},B={2,3,4}A = \{1, 2, 3\}, B = \{2, 3, 4\}
- A△B={1,4}A \triangle B = \{1, 4\}
파이썬 구현:
또는:
파이썬 집합 연산 요약
연산연산자메서드설명
| 교집합 | & | A.intersection(B) | 두 집합의 공통 원소 |
| 합집합 | ` | ` | A.union(B) |
| 차집합 | - | A.difference(B) | 한 집합에만 포함된 원소 |
| 대칭 차집합 | ^ | A.symmetric_difference(B) | 하나의 집합에만 포함된 원소 |
실생활 활용 예제
- 학생 데이터 처리:
- 교집합: 두 수업 모두 들은 학생.
- 합집합: 두 수업 중 하나라도 들은 학생.
- 차집합: 한 수업에만 등록한 학생.
python코드 복사class_A = {"Alice", "Bob", "Charlie"} class_B = {"Bob", "Charlie", "David"} print("교집합:", class_A & class_B) # 출력: {'Bob', 'Charlie'} print("합집합:", class_A | class_B) # 출력: {'Alice', 'Bob', 'Charlie', 'David'} print("차집합:", class_A - class_B) # 출력: {'Alice'} - 파일 비교:
- 교집합: 두 디렉토리에 공통된 파일.
- 합집합: 전체 파일 목록.
- 차집합: 특정 디렉토리에만 있는 파일.
집합 연산은 데이터 비교, 필터링, 검색 등에 유용하며, 효율적인 데이터 처리를 지원합니다.


'sbs 아카데미 학원 수업 > 파이썬 수업 메모 (SBS 아카데미 학원)' 카테고리의 다른 글
| 파이썬 수업 메모 7일차 - 클래스, 상속, try-expect (2) | 2024.12.07 |
|---|---|
| 파이썬 수업 6일차 - 함수 (2) | 2024.12.01 |
| 파이썬 수업 4일차- 문자열 (0) | 2024.11.24 |
| 파이썬 수업 3일차 - While, break, Continue (Sbs아카데미) (0) | 2024.11.23 |
| 파이썬 수업 2일차 - input, 조건문 (Sbs아카데미) (0) | 2024.11.17 |



