https://colab.research.google.com/drive/
Google Colab Notebook
Run, share, and edit Python notebooks
colab.research.google.com

파이썬의 함수는 코드 재사용과 모듈화에 중요한 도구입니다. 주요 개념은 다음과 같습니다:
1. 함수 정의
함수는 def 키워드를 사용해 정의하며, 이름을 붙이고 필요한 경우 매개변수를 추가할 수 있습니다. 함수는 값을 반환하거나 단순히 작업을 수행할 수 있습니다.

2. 구성 요소
- 함수 이름: 호출하기 위한 이름으로 변수와 같은 규칙을 따릅니다.
- 매개변수: 함수에 전달되는 값으로, 함수 내에서 사용됩니다.
- 반환값: 함수 실행 결과를 반환하며, return 키워드를 사용합니다.

3. 매개변수의 종류
- 위치 매개변수: 값을 순서대로 전달합니다.
- 키워드 매개변수: 매개변수 이름을 명시적으로 지정하여 값을 전달합니다.
- 기본값 매개변수: 매개변수에 기본값을 설정해, 값을 전달하지 않을 경우 기본값을 사용합니다.
- 가변 매개변수: *args를 사용해 여러 개의 값을 튜플 형태로 받습니다.
- 가변 키워드 매개변수: **kwargs를 사용해 키와 값을 딕셔너리 형태로 받습니다.



4. 반환값
함수는 결과를 하나 또는 여러 개 반환할 수 있습니다. 여러 값을 반환할 경우, 반환값은 튜플 형태로 전달됩니다.

5. 람다 함수
람다 함수는 이름이 없는 익명 함수로, 간단한 작업을 처리할 때 사용됩니다. 일반적으로 한 줄로 작성되며, 식을 반환합니다.

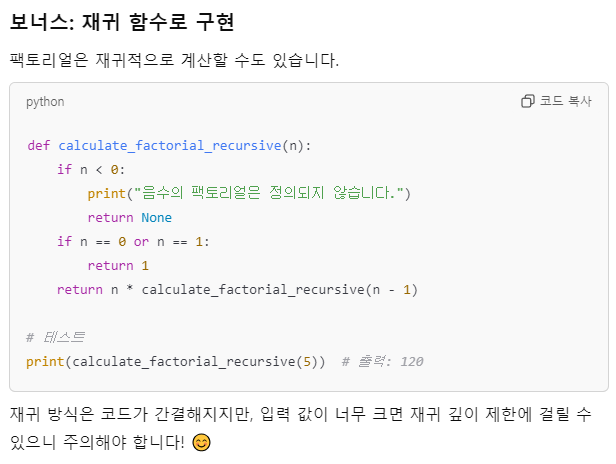
6. 재귀 함수
재귀 함수는 자기 자신을 호출하는 함수로, 반복적인 작업이나 알고리즘에 사용됩니다. 종료 조건을 설정하지 않으면 무한 루프에 빠질 수 있으니 주의가 필요합니다.

7. 내부 함수
함수 안에 또 다른 함수를 정의할 수 있습니다.






콜백 함수 (Callback Function)
콜백 함수란 다른 함수의 인자로 전달되어, 특정 시점이나 조건에서 호출되는 함수를 의미합니다. 주로 비동기 프로그래밍, 이벤트 처리, 또는 함수 실행 흐름을 제어할 때 사용됩니다.
콜백 함수는 다음과 같은 특징을 가집니다:
- 다른 함수의 인자로 전달됩니다.
- 필요한 시점에 호출됩니다.
- 이름 있는 함수나 **익명 함수(람다)**가 될 수 있습니다.
콜백 함수의 동작 방식
- 함수 A가 콜백 함수(함수 B)를 전달받음.
- 함수 A는 실행 중 적절한 시점에 **콜백 함수(함수 B)**를 호출.
- 결과적으로, 함수 B는 함수 A에 의해 실행됩니다.



콜백 함수가 필요한 이유
- 코드 재사용성: 동일한 동작을 여러 상황에서 호출 가능.
- 유연한 함수 설계: 함수를 더 범용적으로 만듦.
- 비동기 작업 처리: 특정 작업이 완료된 후 실행해야 할 코드를 캡슐화.
- 이벤트 중심 프로그래밍: GUI나 서버 이벤트 처리에서 이벤트 발생 시 실행.
콜백 함수의 단점과 해결책
- 복잡성 증가: 콜백이 중첩되면 코드가 읽기 어려워집니다. 이를 **콜백 지옥(callback hell)**이라고 합니다.
- 해결책: Promise, async/await 같은 비동기 처리 방식을 사용.
- 디버깅 어려움: 호출 경로를 따라가기가 어렵습니다.
- 해결책: 콜백 함수 이름 명시화, 람다 사용 최소화.
콜백 함수는 유연한 함수 호출이 필요한 곳에서 매우 유용합니다. 간단한 예제를 만들어 보거나, 이벤트 처리 흐름에서 테스트하면 이해가 더 쉬워질 겁니다! 😊



문제: 최댓값과 최솟값 찾기
다음 조건을 만족하는 함수를 작성하세요:
- 함수 이름은 find_min_max입니다.
- 이 함수는 숫자로 이루어진 리스트를 매개변수로 받습니다.
- 리스트 내에서 최댓값과 최솟값을 찾아서 튜플 형태로 반환합니다.
- 반환값: (최솟값, 최댓값)
- 빈 리스트가 입력될 경우, "리스트가 비어 있습니다."라는 메시지를 출력한 뒤 None을 반환합니다.

답

코드 설명
- 입력값 확인:
- if not numbers:를 사용하여 리스트가 비어 있는지 확인합니다. 비어 있다면 메시지를 출력하고 None을 반환합니다.
- 최솟값과 최댓값 찾기:
- min(numbers)는 리스트에서 최솟값을 반환하고, max(numbers)는 최댓값을 반환합니다.
- 두 값을 튜플 형태로 (min, max)로 묶어서 반환합니다.
- 결과 출력:
- 리스트가 비어 있지 않으면 (최솟값, 최댓값) 형태로 출력됩니다.
문제 2: 리스트 내 중복된 요소 제거하기
다음 조건을 만족하는 함수를 작성하세요:
- 함수 이름은 remove_duplicates입니다.
- 이 함수는 숫자로 이루어진 리스트를 매개변수로 받습니다.
- 리스트에서 중복된 요소를 제거하고, 정렬된 새로운 리스트를 반환합니다.
- 빈 리스트가 입력될 경우, 빈 리스트를 반환합니다.


코드 설명
- 입력값 확인:
- if not numbers:로 리스트가 비어 있는지 확인합니다. 비어 있으면 빈 리스트 []를 반환합니다.
- 중복 제거:
- set(numbers)를 사용하여 리스트에서 중복 요소를 제거합니다.
- 집합(set)은 중복을 허용하지 않으므로 중복된 숫자가 자동으로 제거됩니다.
- 정렬:
- sorted()를 사용하여 집합을 정렬된 리스트로 변환합니다.
- 결과 반환:
- 중복이 제거되고 정렬된 리스트를 반환합니다.
문제 3: 팩토리얼 계산하기
다음 조건을 만족하는 함수를 작성하세요:
- 함수 이름은 calculate_factorial입니다.
- 이 함수는 정수 n을 매개변수로 받습니다.
- 입력값 n의 팩토리얼을 계산하여 반환합니다.
- 팩토리얼 공식: n!=n×(n−1)×(n−2)×⋯×1
- 예: 5!=5×4×3×2×1=120
- 입력값 n이 0 또는 1일 경우, 결과는 1입니다.
- 음수가 입력될 경우, "음수의 팩토리얼은 정의되지 않습니다."라는 메시지를 출력한 뒤 None을 반환합니다.


코드 설명
- 음수 입력 처리:
- if n < 0:를 사용해 음수가 입력되었는지 확인합니다.
- 음수일 경우 에러 메시지를 출력하고 None을 반환합니다.
- 0과 1의 팩토리얼:
- 팩토리얼은 0!과 1!이 모두 1로 정의되므로 별도로 처리합니다.
- 팩토리얼 계산:
- 반복문 for를 사용해 2부터 n까지의 숫자를 곱합니다.
- 매 반복마다 결과를 factorial 변수에 저장합니다.
- 결과 반환:
- 계산된 팩토리얼 값을 반환합니다.
read() 함수
파이썬의 read() 함수는 파일 객체에서 내용을 읽어오는 함수로, 주로 텍스트 파일 처리에 사용됩니다. 파일 내용을 한 번에 모두 읽어와 문자열로 반환합니다.
기본 동작
- 파일 열기: 파일을 읽기 모드('r')로 엽니다.
- 내용 읽기: read()를 사용해 파일 내용을 가져옵니다.
- 파일 닫기: 작업이 끝나면 파일을 닫습니다.

주요 특징
- 전체 내용을 문자열로 반환:
- 파일의 모든 내용을 한꺼번에 가져옵니다.
- 파일 크기가 너무 크면 메모리 사용량이 증가하므로 주의해야 합니다.
- 파일 포인터 이동:
- read()를 호출하면 파일 포인터가 끝으로 이동합니다.
- 다시 읽으려면 파일 포인터를 시작으로 돌려야 합니다. (seek(0) 사용)
- 빈 파일:
- 파일이 비어 있으면 빈 문자열('')을 반환합니다.
read() 함수의 매개변수
read(size) 형태로 사용하며, size는 읽어올 바이트 수를 지정합니다.
- size가 생략된 경우: 파일의 모든 내용을 읽습니다.
- size를 지정한 경우: 지정된 바이트 수만큼 읽어옵니다.

주의사항
- 메모리 사용:
- read()는 파일 전체를 메모리에 올리므로, 파일 크기가 크면 메모리 부족 문제가 발생할 수 있습니다.
- 대안으로 readlines()나 반복문을 사용해 줄 단위로 읽는 방법이 있습니다.
- 파일 모드:
- 파일이 쓰기 모드('w')나 추가 모드('a')로 열려 있다면 read()를 사용할 수 없습니다.
- 읽기 모드('r' 또는 'r+')로 파일을 열어야 합니다.
관련 함수
- readline():
- 한 줄만 읽어옵니다.
- readlines():
- 파일의 모든 줄을 리스트 형태로 반환합니다.
- seek():
- 파일 포인터를 이동시킵니다.


input() 함수
파이썬의 input() 함수는 사용자로부터 데이터를 입력받을 때 사용됩니다. 이 함수는 입력받은 데이터를 항상 문자열(string) 형태로 반환합니다.
기본 사용법
input() 함수는 호출 시 사용자에게 입력을 요청하고, 입력받은 데이터를 반환합니다.





input() 함수의 동작 흐름
- 프로그램이 input() 호출.
- 사용자 입력을 대기.
- 사용자가 데이터를 입력하고 Enter를 누름.
- 입력값을 문자열로 반환.
주의사항
- 형 변환 필요성:
- input()은 항상 문자열로 반환되므로, 숫자나 다른 데이터 형식으로 사용하려면 형 변환이 필요합니다.
- 예: int(), float()
- 빈 입력값 처리:
- 사용자 입력이 없을 경우, 빈 문자열("")이 반환되므로 조건문으로 처리하는 것이 좋습니다.
- 오류 방지:
- 숫자 입력 시 문자를 입력하면 변환 오류가 발생합니다. 이를 방지하려면 try-except 블록을 사용합니다.

요약
- input()은 사용자 입력을 기다리고 문자열로 반환하는 함수입니다.
- 숫자 등 다른 형식으로 사용하려면 형 변환이 필요합니다.
- 조건문이나 예외 처리를 통해 입력값을 검증하는 것이 좋습니다.
재귀 (Recursion)와 재귀 함수
**재귀(Recursion)**란 함수가 자기 자신을 호출하는 프로그래밍 기법입니다. 재귀는 특정 문제를 작은 단위의 동일한 문제로 분할하여 해결할 때 유용합니다.
재귀 함수란?
- 정의: 함수 내부에서 자기 자신을 호출하는 함수.
- 구조:
- 기본 조건(Base Case): 재귀 호출을 멈추기 위한 조건.
- 재귀 단계(Recursive Step): 함수가 자기 자신을 호출하여 문제를 해결하는 단계.
재귀 함수의 동작 원리
재귀는 스택(Stack) 구조를 사용합니다.
- 함수를 호출할 때, 현재 작업이 스택에 저장됩니다.
- 재귀 호출이 끝난 후, 스택에 저장된 작업을 차례로 처리합니다.
재귀 함수의 작성 규칙
- Base Case를 반드시 정의해야 합니다.
- 재귀 호출을 중지할 조건이 없으면 무한 루프에 빠지고, 프로그램이 멈춥니다.
- 문제를 점점 더 작은 크기로 줄여야 합니다.
- 매 재귀 호출마다 문제의 크기가 줄어들지 않으면 무한 루프에 빠질 수 있습니다.
재귀 함수의 장점
- 문제를 더 간결하고 직관적으로 표현:
- 수학적 정의에 가까운 코드 작성 가능.
- 예: 팩토리얼, 피보나치.
- 복잡한 문제를 작은 단위로 나누어 해결:
- 분할정복(Divide and Conquer) 알고리즘에 활용.
- 예: 병합 정렬, 퀵 정렬.
재귀 함수의 단점
- 성능 문제:
- 함수 호출이 많아지면 스택 메모리를 초과할 위험이 있음.
- 이를 **스택 오버플로(Stack Overflow)**라고 함.
- 비효율성:
- 동일한 값이 여러 번 계산될 수 있음.
- 예: 피보나치에서 동일 값을 반복 계산.
- 해결책: 메모이제이션(Memoization) 또는 반복문 사용.
재귀와 반복문 비교
- 재귀:
- 간결하고 직관적이지만 성능 문제가 있을 수 있음.
- 적합: 수학적 정의, 트리 탐색, 분할정복.
- 반복문:
- 메모리 효율적이며 대부분의 재귀를 반복문으로 변환 가능.
- 적합: 단순 반복 작업.
요약
- 재귀 함수는 자기 자신을 호출하며 문제를 분할해 해결.
- 항상 Base Case와 Recursive Step을 명확히 정의.
- 복잡한 문제를 간단히 해결할 수 있지만 성능 문제를 주의.
- 메모이제이션 같은 최적화를 통해 효율성을 높일 수 있음.
'sbs 아카데미 학원 수업 > 파이썬 수업 메모 (SBS 아카데미 학원)' 카테고리의 다른 글
| 파이썬 수업 메모 7일차 - 클래스, 상속, try-expect (2) | 2024.12.07 |
|---|---|
| 파이썬 수업 5일차 range,split,딕셔너리(Dictionary),튜플 (3) | 2024.11.30 |
| 파이썬 수업 4일차- 문자열 (0) | 2024.11.24 |
| 파이썬 수업 3일차 - While, break, Continue (Sbs아카데미) (0) | 2024.11.23 |
| 파이썬 수업 2일차 - input, 조건문 (Sbs아카데미) (0) | 2024.11.17 |



